
The emotiphone has a built-in feature called Rosetta which transfers text to voice and vice versa. In hearing-to-deaf communication, the software recognizes a speaker’s tone, inflection, and volume: the resulting text will emulate these feelings by altering the font size, color, and shape. In deaf-to-hearing exchanges, adding one of twenty-four preselected emoticons after a phrase or sentence alters the emphasis, resonance, and stress of the voice output to reflect the user’s mood.

The emotiphone has
a built-in feature called Rosetta which transfers text to voice and vice versa. In hearing-to-deaf communication, the software
recognizes a speaker’s tone, inflection, and volume: the resulting text will emulate these feelings by altering the font size, color,
and shape. In deaf-to-hearing exchanges, adding one of twenty-four preselected emoticons after a phrase or sentence alters the
emphasis, resonance, and stress of the voice output to reflect the user’s mood.

The emotiphone has
a built-in feature called Rosetta which transfers text to voice and vice versa. In hearing-to-deaf communication, the software
recognizes a speaker’s tone, inflection, and volume: the resulting text will emulate these feelings by altering the font size, color,
and shape. In deaf-to-hearing exchanges, adding one of twenty-four preselected emoticons after a phrase or sentence alters the
emphasis, resonance, and stress of the voice output to reflect the user’s mood.
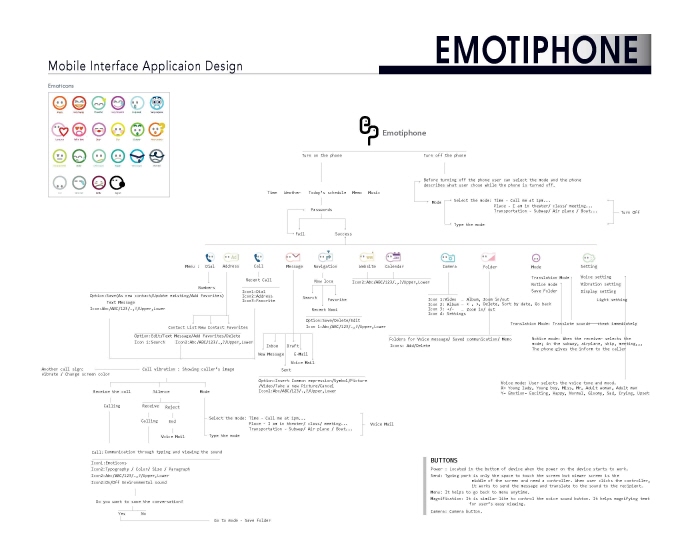
The emotiphone has
a built-in feature called Rosetta which transfers text to voice and vice versa. In hearing-to-deaf communication, the software
recognizes a speaker’s tone, inflection, and volume: the resulting text will emulate these feelings by altering the font size, color,
and shape. In deaf-to-hearing exchanges, adding one of twenty-four preselected emoticons after a phrase or sentence alters the
emphasis, resonance, and stress of the voice output to reflect the user’s mood.
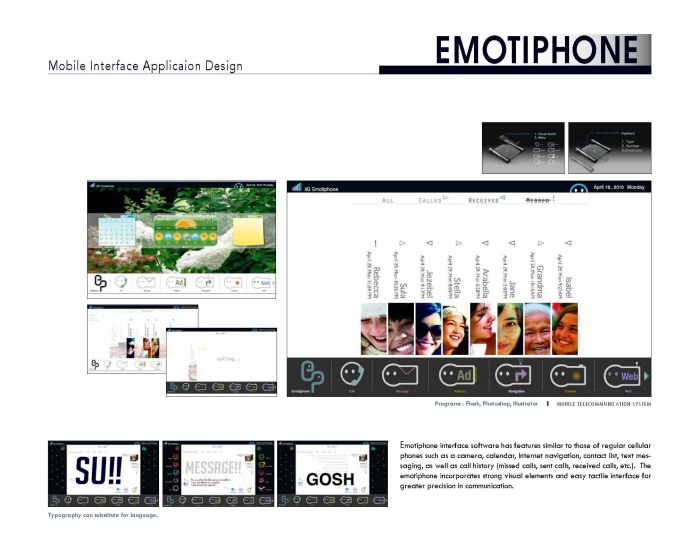
The emotiphone has
a built-in feature called Rosetta which transfers text to voice and vice versa. In hearing-to-deaf communication, the software
recognizes a speaker’s tone, inflection, and volume: the resulting text will emulate these feelings by altering the font size, color,
and shape. In deaf-to-hearing exchanges, adding one of twenty-four preselected emoticons after a phrase or sentence alters the
emphasis, resonance, and stress of the voice output to reflect the user’s mood.
gLike
Mobile Communication System for the Hearing Imapaired
Mobile Communication System for the Hearing Impaired